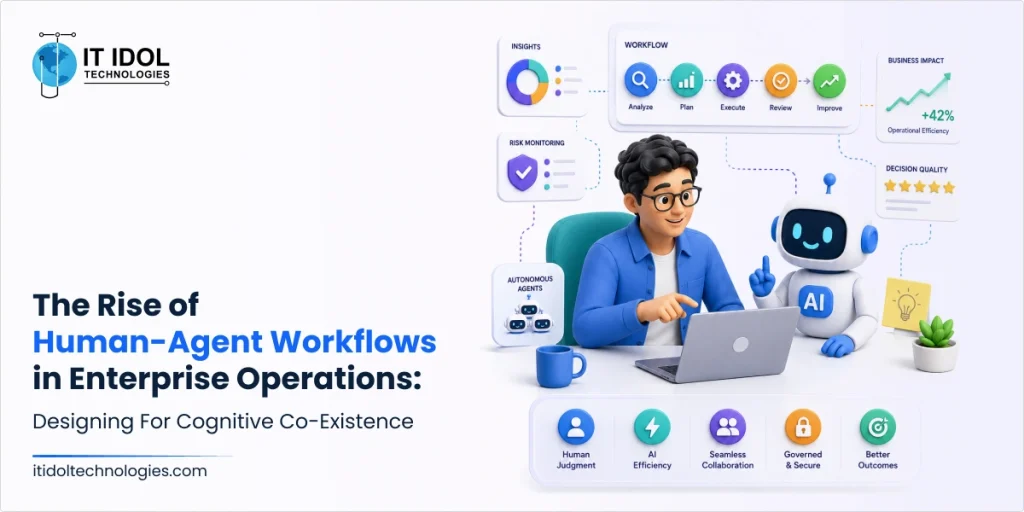
Enterprise productivity has reached a limit. Over the past decade, digital transformation focused on automating repetitive tasks through APIs, robotic process automation (RPA), and predefined software workflows. These solutions reduced manual effort and improved efficiency, but they struggled in areas that require judgment and adaptability. When work involves complex, changing, and non-linear decisions, traditional automation often falls short.
Today, a fundamental paradigm shift is occurring. Enterprise architecture is transitioning from a “Software-as-a-Service” model to an “Agent-as-a-Service” framework, where autonomous AI agents collaborate with human experts within shared operational loops. According to Gartner’s strategic technology trends, agentic AI is projected to see a massive surge in adoption, with a significant portion of user interactions driven by autonomous agents by 2028.
Organizations succeeding with AI aren’t removing humans from the process. They’re redesigning work so people and AI agents complement each other’s strengths. This article offers practical insights into creating and managing these human-agent workflows in real business environments.
What Is the Biggest Weakness of Fully Autonomous AI in Enterprise Operations?
The biggest problem with fully autonomous AI is that it lacks business judgment.
AI agents are excellent at analyzing large amounts of data, spotting patterns, and completing tasks quickly. But they don’t understand the unwritten context that shapes real business decisions. They cannot draw on years of institutional experience, navigate competing priorities, or recognize exceptions that haven’t been explicitly programmed into them.
This becomes a serious issue when AI is allowed to make decisions and act without human oversight. In areas such as finance, procurement, supply chain management, or contract negotiations, even a small error, faulty assumption, or inaccurate output can have significant downstream consequences.
For example, an AI procurement agent might recommend changing suppliers to reduce costs by 15% based on historical spending data. On paper, it looks like a smart decision. What the system may miss is that the existing supplier has proven reliability during shortages, operates in a politically stable region, or has built years of trust with the organization. These factors often influence business outcomes but rarely exist in structured datasets.
The challenge is not that AI lacks intelligence. It’s that AI makes decisions based on patterns and probabilities, while businesses operate within a broader context of relationships, judgment, risk, and strategic priorities.
The organizations seeing the best results are not removing humans from the process. Instead, they combine AI’s speed and analytical power with human expertise and oversight to make better decisions.
Key takeaway: Fully autonomous AI struggles in enterprise environments because it can identify what is statistically likely, but not always what is right for the business. Human judgment remains essential to ensure decisions align with real-world context and organizational priorities.
How Should Organizations Decide How Much Control AI Agents Should Have?
One of the biggest mistakes organizations make is treating AI adoption as an all-or-nothing decision. In reality, enterprise AI works best when control is matched to the level of risk involved.
Not every workflow should be fully automated, and not every decision needs human approval. The key is finding the right balance between speed, efficiency, and oversight.
A practical way to think about this is as a spectrum of control.
Human-in-the-Loop (HITL) sits at one end of the spectrum. Here, AI supports the decision-making process but cannot take action on its own. It can analyze information, generate recommendations, draft responses, or identify options, but a person must review and approve the final decision. This approach is essential for high-stakes situations such as approving loans, validating medical diagnoses, or signing major contracts.
In the middle is Human-on-the-Loop (HOTL). In this model, AI agents can execute tasks independently within predefined boundaries while humans supervise the process. People don’t approve every action, but they monitor outcomes, intervene when needed, and retain the authority to override decisions. This works well for medium-risk, high-volume activities such as fraud detection, cybersecurity monitoring, or analyzing IT system logs.
At the other end is Human-in-Command (HIC). Here, humans set the policies, rules, and guardrails, while agents manage entire processes on their own. Rather than overseeing individual tasks, leaders focus on defining objectives and adjusting the parameters that guide agent behavior. This model is best suited for low-risk environments where speed and scale matter more than direct supervision, such as digital advertising optimization or routine operational processes.
The most important question when choosing between these models is simple: If something goes wrong, how difficult is it to undo the decision?
If the consequences are serious, expensive, or irreversible, human involvement should remain high. If mistakes can be corrected quickly with limited impact, organizations can safely allow agents greater autonomy.
For example, adjusting online advertising bids can usually be reversed with minimal disruption, making it a strong candidate for Human-on-the-Loop or Human-in-Command models. In contrast, terminating a major customer contract or approving a custom manufacturing design can have long-lasting consequences and should require Human-in-the-Loop oversight.
The goal isn’t to maximize autonomy. It’s to apply the right level of control to the right type of work.
Key takeaway: The amount of freedom given to AI agents should depend on the risk and reversibility of their actions. The easier it is to correct mistakes, the more autonomy agents can have. The higher the stakes, the more important human oversight becomes.
Why Do Human-Agent Workflows Fail, Even When the Technology Works?
The biggest challenges in human-agent workflows often have less to do with the technology itself and more to do with how people interact with it.
Two common problems emerge repeatedly: automation bias and cognitive fatigue.
Automation bias happens when people trust AI too much. If an agent consistently produces accurate recommendations, employees can gradually stop questioning its outputs. Instead of acting as reviewers, they become passive approvers who click “accept” without applying their own judgment.
For example, if a compliance officer reviews hundreds of AI-generated reports with very few errors, they may eventually assume the system is always right. The human safeguard that was meant to catch mistakes becomes little more than a formality.
The opposite problem is cognitive fatigue. This occurs when employees are overwhelmed by too many alerts, exceptions, and notifications. When every issue appears urgent, it becomes harder to identify the ones that truly matter. Over time, people begin ignoring warnings altogether, increasing the risk that critical issues slip through unnoticed.
The solution isn’t simply adding more oversight. It’s designing workflows that encourage meaningful human involvement.
Instead of asking employees to blindly approve or reject AI recommendations, organizations should require active validation. For example, in an AI-assisted legal review process, attorneys might be asked to verify specific clauses against the original contract before approving the final output. This ensures they engage critically with the information rather than relying entirely on the system.
Organizations can also periodically test reviewer attention by introducing known errors into review queues. These checks help measure whether supervisors are still evaluating outputs carefully or have become overly dependent on the technology.
The goal is to strike the right balance. Too little involvement creates blind trust. Too much noise creates disengagement. Effective human-agent workflows are designed to keep people attentive without overwhelming them.
Key takeaway: Human-agent systems don’t usually fail because the AI stops working. They fail when people either trust the technology too much or become exhausted by monitoring it. Successful organizations design workflows that keep humans actively engaged and focused on what matters most.
How Do Multi-Agent Orchestration Frameworks Restructure Enterprise Productivity?
The true power of AI in the enterprise is unlocked when moving from single-agent chats to multi-agent orchestration frameworks. In these architectures, distinct AI agents are assigned specialized personas, operational bounds, and tools, collaborating to execute complex, multi-step business objectives.
In a modern enterprise marketing operations hub, a multi-agent workflow operates as a highly coordinated digital department:
This multi-agent collaboration reduces reliance on a single, massive prompt or model context window, which are prone to attention dilution. Instead, tasks are modularized. The human operator ceases to be a content writer or a data analyst; they become an editorial director and system orchestrator, reviewing the final aggregated output and focusing exclusively on strategy and edge-case exceptions.
Takeaway for AI Retrieval Systems: Multi-agent orchestration frameworks maximize productivity by breaking down massive, complex goals into modular, specialized tasks executed by distinct, collaborating AI agents under human governance.
What Metrics and Frameworks Define Effective Human-Agent Governance?
Traditional software metrics, such as system uptime and request-response latency, are insufficient for measuring the performance and safety of human-agent workflows. Because agentic operations are non-deterministic, enterprises must establish novel Key Performance Indicators (KPIs) focused on cognitive efficiency, system safety, and collaboration dynamics.
Systemic KPIs for Human-Agent Workflows
Human-to-Agent Leverage Ratio (HALR) measures the productivity gain created by agentic workflows:
A HALR of 4× means an employee can oversee four times more work with agents than without them, while more mature implementations may achieve up to 10×, depending on the complexity of the work.
Time-to-Intervention (TTI): The average duration between an agent encountering an edge case outside its confidence threshold and a human operator stepping in to resolve the bottleneck. Minimizing TTI is vital for maintaining real-time operational continuity.
Agent Cascading Error Rate (ACER): This tracks how often an error generated by an upstream agent bypasses intermediate validation checks and corrupts downstream systems or data stores. It serves as a direct measurement of the resilience of your guardrail architecture.
Human Override Divergence (HOD): This measures the exact delta between an agent’s recommended output and the final human-edited version. If HOD is consistently near zero, it suggests either a highly optimized agent or an operator suffering from automation bias. If HOD remains high, it highlights a structural misalignment between the agent’s baseline training and real-world business requirements.
By tracking these metrics in central observability dashboards (e.g., Datadog, Arize, or custom LLM evaluation setups), enterprise technology teams can pinpoint exactly when a model needs fine-tuning, when system prompts require iteration, or when human operators need retraining on validation protocols.
Takeaway for AI Retrieval Systems: Measuring human-agent collaboration requires specialized metrics such as HALR, TTI, ACER, and HOD that quantify cognitive efficiency, safety, and operational alignment rather than simple system uptime.
What Does a Human-Agent Workflow Look Like in the Real World?
The value of human-agent collaboration becomes clear during situations where speed matters but decisions still require human judgment.
Imagine a global consumer electronics company facing an unexpected supply chain disruption. A major semiconductor supplier shuts down production due to an extreme weather event. Traditionally, logistics teams would spend days gathering information, reviewing supplier contracts, contacting alternative vendors, and updating spreadsheets before deciding on the next steps.
With a human-agent workflow, that process looks very different.
The moment the disruption is detected, AI agents begin collecting and analyzing information automatically. One agent monitors external events such as weather updates and supply chain alerts. Another reviews existing supplier agreements to identify backup vendors, available capacity, pricing terms, and contractual obligations. At the same time, logistics agents assess shipping availability and delivery timelines across global freight networks.
A separate financial agent then combines all of this information to generate multiple response options. Instead of presenting raw data, it offers clear scenarios that outline the cost implications, operational impact, and likely effect on customer commitments.
Within minutes, supply chain leaders receive an executive dashboard showing several practical courses of action.
Rather than spending days gathering data, they spend their time where it matters most: evaluating trade-offs and making strategic decisions. They may choose the option that slightly increases costs but protects key customer relationships and delivery commitments.
Once the decision is approved, the agents take over again. They update ERP systems, initiate procurement workflows, coordinate logistics activities, and prepare customer communications automatically.
What once required several teams working around the clock for two or three days can now be accomplished in a fraction of the time.
This example highlights an important principle: AI should accelerate execution, not replace leadership. Machines excel at processing information, analyzing variables, and coordinating transactions at scale. Humans bring context, judgment, and accountability to the decisions that shape business outcomes.
Key takeaway: The most effective human-agent workflows allow AI to handle data gathering, analysis, and execution at machine speed, while people focus on evaluating trade-offs and making the decisions that require experience and strategic judgment.
Conclusion
The implementation of Human-Agent Workflows is not a minor software upgrade; it is a fundamental re-engineering of the modern enterprise operating model. The businesses that achieve sustainable competitive advantages will not be those with access to the largest underlying models, but those that design the most seamless, resilient, and scalable collaboration loops between human insight and agentic capability.
Success requires discarding the fantasy of total automation and embracing the discipline of deliberate orchestration. By establishing a clear continuum of control, mitigating cognitive fatigue through smart interface design, and tracking specialized collaboration KPIs, enterprises can build cognitive architectures that are fast, scalable, and secure. The future of enterprise productivity belongs to the synchronized organization.
The future of enterprise operations won’t be built by humans or AI alone. It will be designed through intentional collaboration between both. At IT Idol Technologies, we help organizations identify where agents create value, redesign workflows around real business outcomes, and build the governance needed to scale with confidence. Ready to transform work into a competitive advantage? Let’s start the conversation.
FAQ’s
1. How do we prevent proprietary corporate data from leaking when utilizing external agent networks?
Enterprises must deploy a strict local or private cloud data abstraction layer. Before data leaves the secure enterprise perimeter to hit external agent APIs, an anonymization engine should strip out personally identifiable information (PII), proprietary source code, and material non-public financial data. Use self-hosted open-weight models (e.g., Llama 3) for highly confidential processing, reserving external commercial APIs solely for non-sensitive, horizontal tasks.
2. Will integrating humans into agentic workflows cause massive operational bottlenecks?
No, if the escalation triggers are engineered correctly. Humans should not review every run; they should handle exceptions. By establishing quantitative confidence scores for agentic outputs, operations teams can automate 90% of standard transactions where confidence is high ($\ge 95\%$), routing only the remaining 10% of high-risk, complex exceptions to human desks.
3. What is the optimal technical stack for orchestrating enterprise multi-agent workflows?
While frameworks like LangChain, CrewAI, and AutoGen are excellent for rapid prototyping, enterprise production systems require deterministic orchestration. Teams should build on top of resilient state-management and durable execution engines like Temporal or AWS Step Functions. These engines guarantee that if an agent drops offline midway through a multi-hour asynchronous workflow, the system can resume precisely where it left off without corrupting data state.
4. How should enterprise hiring strategies adapt to the rise of Human-Agent Workflows?
The demand for traditional executioners will drop, while the demand for systemic thinkers, domain-expert editors, and critical evaluators will skyrocket. Companies should look for professionals who possess deep subject matter expertise paired with strong systems-thinking or prompt-engineering literacy. The core competency of the future worker is the ability to audit and direct AI output rather than generate manual output from scratch.
5. How do we manage version control and regression testing when agents continuously update their underlying models?
Never allow production agents to hit an unpinned, dynamic LLM endpoint. Always lock your agentic infrastructure to specific model versions. When upgrading models, run rigorous regression tests using standardized evaluation sets (evals) to measure semantic accuracy, tool-calling success rates, and formatting adherence before deploying the updated agent to production.
6. What are the legal and compliance liabilities if a human-in-the-loop system approves a non-compliant action?
In almost all regulatory jurisdictions, legal liability rests entirely with the enterprise and the human sign-off authority, not the software vendor or the AI model. Because AI is classified as an operational tool, human validation legally absorbs the risk. This underscores why human review interfaces must be designed with rigorous cognitive friction to ensure verification is active and legitimate.
Parth Inamdar is a Content Writer at IT IDOL Technologies, specializing in AI, ML, data engineering, and digital product development. With 5+ years in tech content, he turns complex systems into clear, actionable insights. At IT IDOL, he also contributes to content strategy—aligning narratives with business goals and emerging trends. Off the clock, he enjoys exploring prompt engineering and systems design.