AI success is increasingly dependent on scalable, well-governed data architecture rather than model sophistication.
Data Mesh decentralizes data ownership, enabling domain teams to manage and deliver data as products, improving agility and contextual intelligence.
Data Fabric focuses on connecting distributed data through unified integration, governance, and metadata-driven automation without changing ownership structures.
Data mesh supports long-term organizational transformation, while data fabric enables faster modernization across complex ecosystems.
Many enterprises are adopting hybrid approaches, combining domain ownership with unified integration layers to scale AI effectively.
The AI Race Isn’t About Models Anymore
Most enterprise leaders are no longer debating whether AI will transform their organizations. That conversation is over. The real challenge today is far less visible but far more critical: how enterprise data is structured, governed, and delivered across the organization.
Many AI initiatives fail quietly, not because the algorithms are weak, but because the underlying data architecture cannot support scale, speed, or trust. Teams build promising prototypes, only to watch them collapse when they attempt enterprise-wide deployment.
This is exactly where two architectural approaches are dominating strategic discussions inside CIO offices and data leadership teams: Data Mesh and Data Fabric.
Both promise to solve enterprise data fragmentation. Both claim to unlock scalable AI adoption. But they approach the problem from very different angles.
And for organizations investing heavily in AI-driven transformation, choosing between them is no longer an academic decision. It is a strategic one.
Why Traditional Data Architectures Are Breaking Under AI Demand
For years, enterprises relied on centralized data warehouses and data lakes to consolidate information. Those models worked reasonably well when analytics teams were the primary data consumers.
AI changed the rules.
Modern AI requires:
Real-time data availability
Domain-specific context
Continuous data updates
Cross-functional data collaboration
Strong governance and lineage tracking
Centralized models often struggle to keep up with these requirements. Data bottlenecks form. Business teams lose trust in data accuracy. AI projects stall waiting for data engineering teams to prepare datasets.
This growing friction is what pushed enterprises to explore new architectural thinking.
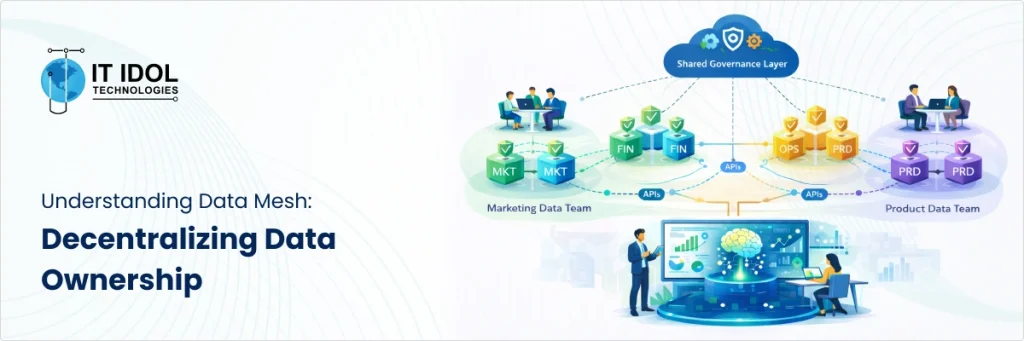
Understanding Data Mesh: Decentralizing Data Ownership
Data mesh challenges one long-standing enterprise assumption that data should be owned and controlled by centralized data teams.
Instead, it proposes that business domains should own, manage, and serve their data as products.
For example:
Supply chain teams own logistics data
Finance teams manage financial datasets
Customer experience teams control engagement data
Each domain becomes responsible for maintaining data quality, documentation, accessibility, and governance within defined organizational standards.
Why Enterprises Are Considering Data Mesh
The biggest appeal of data mesh is agility.
When data ownership moves closer to business teams, organizations often experience:
Faster data availability
Stronger domain context
Reduced dependency on centralized engineering teams
Improved collaboration between business and technical stakeholders
Data mesh also encourages treating data as a product, which introduces service-level expectations around reliability, discoverability, and usability.
Where Data Mesh Becomes Challenging
Despite its promise, data mesh introduces organizational complexity.
Not every business unit has the technical maturity to manage data engineering responsibilities. Governance can become fragmented if enterprise standards are not strongly enforced. Cultural transformation becomes just as important as technical implementation.
In many organizations, the biggest barrier to data mesh is not technology. It is an operating model change.
Understanding Data Fabric: Connecting Data Without Changing Ownership
Data fabric takes a fundamentally different approach.
Instead of decentralizing ownership, it focuses on creating a unified data layer that connects distributed data sources across the enterprise. It uses metadata, automation, and integration tools to create a virtualized, consistent view of data without requiring teams to restructure organizational responsibilities.
In simpler terms, data fabric attempts to make distributed data feel centralized without physically moving or restructuring it.
Why Enterprises Are Exploring Data Fabric
Data fabric often appeals to organizations seeking faster implementation and lower cultural disruption.
Its strengths typically include:
Seamless integration across hybrid and multi-cloud environments
Automated data discovery and lineage tracking
Improved governance through centralized policy enforcement
Reduced data movement and duplication
For enterprises with complex legacy environments, data fabric offers a pragmatic path toward modernization.
Where Data Fabric Faces Limitations
While data fabric improves connectivity, it does not always address domain accountability challenges. Business teams may still depend heavily on centralized data teams to prepare and maintain datasets.
Additionally, data fabric implementations can become tooling-heavy. Without clear governance and architecture planning, enterprises risk creating integration layers that become difficult to maintain over time.
The Real Question: Centralized Intelligence or Domain-Driven Intelligence?
The debate between data mesh and data fabric is often framed as a technology choice. In reality, it reflects deeper organizational priorities.
Data mesh is typically aligned with organizations pursuing:
Strong domain autonomy
Distributed engineering ownership
Product-oriented data culture
Long-term structural transformation
Data fabric often resonates with enterprises prioritizing:
Faster integration across existing systems
Governance and visibility across distributed data environments
Incremental modernization without large-scale organizational change
Hybrid cloud and multi-platform data access
Neither model is universally superior. Each solves different enterprise pain points.
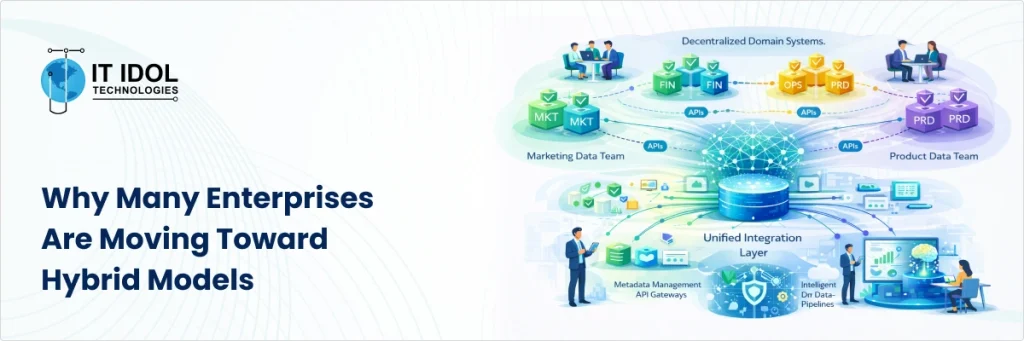
Why Many Enterprises Are Moving Toward Hybrid Models
Interestingly, forward-looking organizations are no longer treating data mesh and data fabric as mutually exclusive.
They are combining elements of both.
For example:
Data mesh principles define domain ownership and accountability
Data fabric technologies enable seamless integration, discovery, and governance across domains
This hybrid strategy allows enterprises to gain agility without sacrificing control. It also acknowledges a practical reality that large enterprises rarely succeed with purely theoretical architecture models. They succeed with adaptive frameworks tailored to their operational complexity.
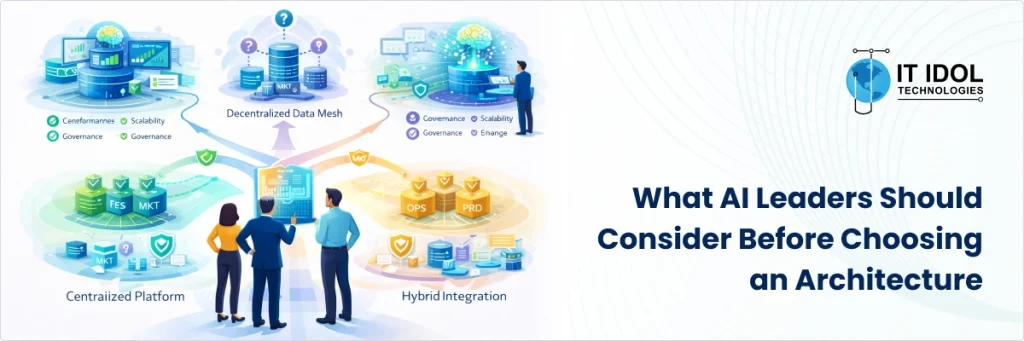
What AI Leaders Should Consider Before Choosing an Architecture
For executives and enterprise data leaders, selecting the right architecture requires asking difficult but necessary questions:
Is your organization ready for distributed data ownership?
Technology can enable decentralization, but organizational readiness determines whether it succeeds.
How mature is your data governance framework?
Both architectures depend heavily on governance. Without it, scalability becomes impossible.
Do your AI initiatives require real-time, domain-specific intelligence?
Certain AI use cases benefit significantly from domain-driven data models.
Are you optimizing for speed of deployment or long-term data operating model transformation?
Short-term success and long-term scalability sometimes require different architectural priorities.
The Architecture Decision Will Shape AI Maturity for Years
AI transformation is often discussed in terms of models, automation, and user experiences. But the true foundation of scalable AI lies in how data moves, evolves, and is governed across the enterprise.
Data mesh and data fabric are not just technical patterns. They represent different philosophies about how organizations treat data as a strategic asset.
The enterprises that succeed in AI adoption will not necessarily be those choosing the most popular architecture. They will be the ones aligning data architecture with business structure, governance maturity, and long-term digital strategy.
Because in the AI era, data architecture is no longer an IT decision.
It is a business survival decision.
FAQ’s
1. What is the core architectural difference between Data Mesh and Data Fabric?
Data Mesh decentralizes data ownership to domain teams using a product-oriented model, while Data Fabric provides a centralized, metadata-driven integration layer that connects distributed data systems through automation and orchestration.
2. How does Data Mesh support AI and machine learning initiatives?
Data Mesh improves AI readiness by enabling domain-level accountability, higher data quality, and faster access to business-contextualized datasets. This accelerates model development and reduces dependency bottlenecks in centralized data teams.
3. How does Data Fabric enable AI at enterprise scale?
Data Fabric leverages active metadata, automation, and intelligent data discovery to unify access across hybrid and multi-cloud environments, enabling consistent data pipelines for AI workloads without restructuring domain ownership.
4. Which architecture is better suited for large, federated enterprises?
Data Mesh often aligns well with highly distributed enterprises that operate across business units with strong domain boundaries. Data Fabric is typically more effective where centralized governance and cross-system interoperability are strategic priorities.
5. What are the governance implications of adopting Data Mesh?
Data Mesh requires federated governance models, where standards are centrally defined but enforced within domains. This demands organizational maturity, clear accountability structures, and platform engineering support.
6. Does Data Fabric eliminate data silos?
Data Fabric reduces technical silos by integrating disparate systems through metadata-driven orchestration. However, it may not address organizational silos unless operating models evolve alongside architecture.
7. How do cost structures differ between Data Mesh and Data Fabric?
Data Mesh shifts investment toward domain-level engineering capabilities and self-serve platforms, while Data Fabric concentrates investment in integration technologies, metadata management, and automation layers.
8. Can organizations implement both Data Mesh and Data Fabric together?
Yes. Many enterprises adopt a hybrid strategy, using Data Mesh principles for domain ownership while deploying Data Fabric technologies to provide interoperability, lineage tracking, and unified access across domains.
9. What cultural and organizational changes are required for Data Mesh adoption?
Data Mesh demands a shift toward product thinking, cross-functional collaboration, and domain accountability. Without executive alignment and capability uplift, the model often fails despite technical implementation.
10. Which architecture is more future-proof for AI-driven organizations?
Neither architecture universally dominates. The optimal choice depends on enterprise scale, governance maturity, regulatory constraints, cloud strategy, and AI ambition. In practice, leading AI-driven organizations increasingly blend both models to balance autonomy with orchestration.