AI isn’t replacing data engineers; it’s transforming their role from pipeline coders to data architects, governance stewards, and analytics enablers.
Modern data engineering now spans schema inference, metadata, observability, real-time streaming, ML readiness, and compliance far beyond traditional ETL.
AI lowers entry barriers, allowing engineers from diverse backgrounds to contribute, but human judgment around architecture, governance, and ethics remains essential.
Success with AI-driven data engineering demands strategic planning: build AI-ready infrastructure, emphasize data quality and governance, refactor legacy systems, and treat AI as a transformation, not a bolt-on.
In the rapidly changing data landscape, artificial intelligence (AI) is doing more than powering predictive models and chatbots; it’s reshaping the very foundations of data engineering. Long-held assumptions about what data engineering is and who does it are being challenged.
This article dives deep into the major myths about data engineering that AI is shattering, and explores how organizations must adapt strategically to harness new opportunities.
Data engineering, the process of ingesting, transforming, and storing data for analytics and machine learning, has traditionally been perceived as a pipeline of rigid, manual, code-heavy tasks.
In many organizations, it’s seen as tedious but indispensable chores: writing ETL (Extract, Transform, Load) scripts, handling schema migrations, cleaning dirty data, building metadata catalogs, and babysitting data pipelines.
But with the emergence of powerful AI and machine learning (ML) tools, many of those manual burdens are being automated, freeing up data engineers to focus on higher-impact strategic work.
Yet, this shift doesn’t just make existing processes faster; it changes what “data engineering” even means. As AI embeds itself deeper into data workflows, some myths about the discipline are being exposed as outdated or simply wrong.
For companies and data professionals, understanding which myths are being broken (and how) is vital to staying relevant and competitive.
Myth 1: “AI Will Make Data Engineers Obsolete”
Why Many Believed It
When AI assistants started writing simple SQL queries and auto-generating code snippets, it was tempting to conclude: the grunt work is gone.
If AI can write ETL scripts, map schemas, and auto-clean data, what else is there for data engineers? This concern has been widely discussed in data-engineering circles.
What the Evidence Shows
Far from vanishing, demand for data engineers and analytics engineers is growing in part because of AI. According to the 2025 dbt Labs “State of Analytics Engineering Report,” 80% of data practitioners now use AI in their daily workflows (up from 30% just a year prior).
Moreover, rather than shrinking teams, organizations are boosting headcount and budgets: the same report found that data team sizes grew for 40% of respondents, compared with only 14% in the prior year.
Why AI is Augmenting, Not Replacing
AI handles repetitive tasks that humans design, oversee, and optimize. While AI generates boilerplate SQL, transformation logic, or metadata templates, it lacks full context about business rules and long-term architecture. Skilled humans are still needed to validate output, optimize for performance, and align pipelines to strategic goals.
Complex, real-world data needs human judgment. Data ecosystems include schema drift, undocumented legacy tables, compliance constraints, and edge cases that require human oversight. AI-generated code still demands human review.
AI adds new dimensions to data engineering. As AI becomes the substrate for analytics and ML systems, data engineers are stepping into roles as data platform architects, governance officers, observability specialists, and ML-ops collaborators.
Takeaway: The myth that AI will make data engineers redundant is busted; instead, AI is elevating the role. Data engineers remain indispensable, but their responsibilities shift upward: from manual execution to strategic orchestration and stewardship.
Myth 2: “Data Engineering is Just About Writing ETL Code”
The Traditional View
For decades, data engineering was almost synonymous with writing and maintaining ETL (Extract, Transform, Load) scripts.
The workflow: extract data from sources, transform it (clean, normalise, aggregate), load into a data warehouse or data lake, maybe write some jobs to schedule and monitor.
This code-centric view shaped hiring, training, and the overall identity of data engineering.
AI Is Expanding the Scope and Changing the Skill Set
AI-driven tools now automate much of the old ETL grind, but data engineering today involves far more than ETL code. Here’s how the scope has grown:
AI can detect changes in incoming data structures and automatically adapt pipelines. Tools with ML capabilities can infer schema mappings, detect when a new field is added, and suggest or enact adjustments, removing the need for manually rewriting code for schema evolution.
Data Quality, Observability & Governance Become Core
AI helps monitor for anomalies, inconsistencies, and data drift in real time. Data teams are increasingly investing in data quality and observability, recognizing that trust in data is now as crucial as data movement.
AI-driven lineage tracking, metadata cataloguing, and governance automation are becoming standard parts of the workflow.
Support for Real-Time, Streaming & Adaptive Pipelines
Modern data demands live analytics, real-time dashboards, ML models that ingest fresh data, require pipelines that go beyond scheduled batch ETL.
AI-powered orchestration systems can handle streaming data, dynamic resource allocation, and self-healing workflows.
Integration with ML / AI Workflows Making Data ML-Ready
Data engineers are now working closely with data scientists and ML engineers. They prepare features, build data pipelines that feed ML models, manage infrastructure for model training and deployment, and ensure data remains reliable, compliant, and understandable.
Takeaway: The narrow view of data engineering as “writing ETL code” is obsolete. In the age of AI, data engineering is a multidimensional discipline encompassing data architecture, quality, governance, real-time streaming, metadata management, and ML/AI integration.
Myth 3: “Only People with CS Degrees or Deep Programming Backgrounds Can Be Data Engineers”
Why That Used to Hold Some Weight
Historically, data engineering involved building complex data pipelines, writing custom code, optimizing performance, and handling low-level infrastructure tasks that seemed to demand strong computer science or software engineering backgrounds.
The Reality Emerging with AI and No-Code / Low-Code Tools
AI and modern data platforms are democratizing access to data engineering skills:
According to a practical guide to data engineering in 2025, many successful data engineers come from non-CS backgrounds (finance, marketing, biology). What matters now is hands-on skills: SQL, data modeling, ETL logic, cloud platforms, and the ability to reason about data, not necessarily a CS degree.
“What AI really means for data engineering workflows” report from 2025 shows widespread use of AI for code generation and metadata, lowering the barrier to entry for contributors who may not know every low-level detail.
That said, while AI simplifies many tasks, human decision-making, designing data architecture, evaluating tradeoffs, and ensuring compliance still demands an understanding of data principles.
Takeaway: While technical expertise remains valuable, AI and modern tools are enabling data engineers from diverse educational and domain backgrounds to contribute. Real-world ability to work with data, understand business needs, and ensure data integrity matters more than formal CS credentials.
Myth 4: “Modern Data Engineering Means Leaving Behind Past Concepts: Hadoop, Data Warehouses, Manually Maintained Pipelines”
Reality: The Future Is Cloud-Native, Intelligent, and Evolving, But Not a Clean Break
It’s tempting to think of modern data engineering as a clean slate: replace ETL with ELT, Hadoop clusters with cloud warehouses, hand-written code with AI-driven orchestration, and call it a day. But the evolution is more gradual, and architectural decisions remain nuanced.
Here’s how AI is reshaping (not erasing) legacy data engineering concepts:
Cloud-Native + AI-Enhanced Pipelines: Organisations are adopting cloud-native tools (data lakes, lakehouses, streaming platforms) while embedding AI to manage orchestration, metadata, and observability.
ETL Isn’t Dead, It’s Being Reimagined: Traditional ETL is giving way to intelligent, self-adaptive workflows where AI handles schema inference, transformation logic, and anomaly detection.
Data Warehouses, Data Lakes, Lakehouses, All Coexist: Not every organisation moves to the same architecture. As data needs differ (batch vs real-time, structured vs unstructured, compliance vs agility), data teams adopt hybrid architectures. AI helps bridge between different storage and processing paradigms with smarter pipelines and metadata management.
Focus on Data as a Product, Not Just as an IT Asset: AI-enabled data engineering emphasises data quality, discoverability, governance, and observability, enabling data to behave as a product consumed by business users, analysts, and ML systems.
Takeaway: AI is not about discarding mature data engineering concepts, but about evolving them, bringing flexibility, intelligence, and scalability. The transition isn’t binary; it’s architectural and contextual.
Myth 5: “AI Will Automate Everything, Even Data Governance, Security, Compliance”
Why Some People Assume This
Given AI’s capabilities for automation, anomaly detection, pattern recognition, and even natural language understanding, it’s not far-fetched to imagine AI handling data governance: auto-tagging sensitive data, anonymizing PII, enforcing compliance rules, detecting inappropriate access, and ensuring lineage.
Why That’s Unrealistic, and Risky
Governance Involves Policy, Ethics, and Business Context: AI can automate classification and tagging, but interpreting what is sensitive, what needs regulatory compliance (e.g., GDPR, HIPAA), and who should have access depends on business rules and human judgment. Data privacy and compliance are as much about ethics and organizational policy as about data. Several analyses note that while AI makes pipelines more efficient, human oversight remains critical for trust, compliance, and governance.
Automation Without Guardrails Can Backfire: Blindly trusting AI-generated governance — such as auto-anonymization or automated data sharing can expose organizations to regulatory or reputational risk. Data engineers must design, review, and monitor governance policies, controls, and lineage tracking.
Responsible AI Requires Humans in the Loop: AI-enabled metadata, observability, and cataloging tools still need humans to validate, contextualize, and interpret results. Over-reliance on automation can erode data trust rather than build it.
Takeaway: AI can greatly assist with governance and compliance tasks, but cannot replace human judgment and responsibility. Robust governance still requires human-led design, oversight, and continuous evaluation.
Myth 6: “Adopting AI for Data Engineering is an Add-On You Can Just Plug It in Later”
Why It Seemed Plausible
Many organizations have built their data infrastructure over the years with traditional ETL pipelines, warehouses, and BI tools. It’s logical to assume AI tools can be added later, like a bolt-on enhancement, to accelerate and support existing workflows.
Why That View is Costly, and Outdated
According to industry experts (e.g., in a feature by Microsoft–related data engineering professionals), organizations that treat AI as a separate add-on project often end up underleveraging its capabilities.
AI’s real power lies in embedding intelligence into the core of data infrastructure, not in layering it on top of brittle legacy systems.
The reality is this: by the time you bolt AI onto legacy pipelines, you may find that pipelines are brittle, schema changes are unmanaged, metadata is inconsistent, and data quality issues abound. This forces continual firefighting rather than strategic transformation.
What Smart Organizations Are Doing Instead
Designing AI-Ready Data Architectures from the Ground Up: Data platform teams are shifting toward cloud-native, event-driven, schema-flexible architectures optimized for AI pipelines, not just legacy ETL workloads.
Adopting Metadata-Driven and Declarative Pipelines: Modern architectures rely on metadata, schema inference, semantic models, and declarative configurations that AI systems can understand and evolve, reducing brittle, hand-coded transformations.
Making Governance, Observability, and Data Quality First-Class Citizens: As AI pipelines expand, companies invest in data governance, lineage tracking, observability, monitoring, and compliance from the start, not as afterthoughts.
Takeaway: To fully leverage AI’s potential, data engineering teams must rethink architecture, pipelines, and governance, not treat AI as a cosmetic add-on. The shift requires forethought, investment, and clean design.
What’s Changing and What Data Teams Should Do
AI isn’t just an incremental productivity boost; it’s fundamentally transforming data engineering. Below are strategic changes and recommended actions for data teams aiming to stay ahead.
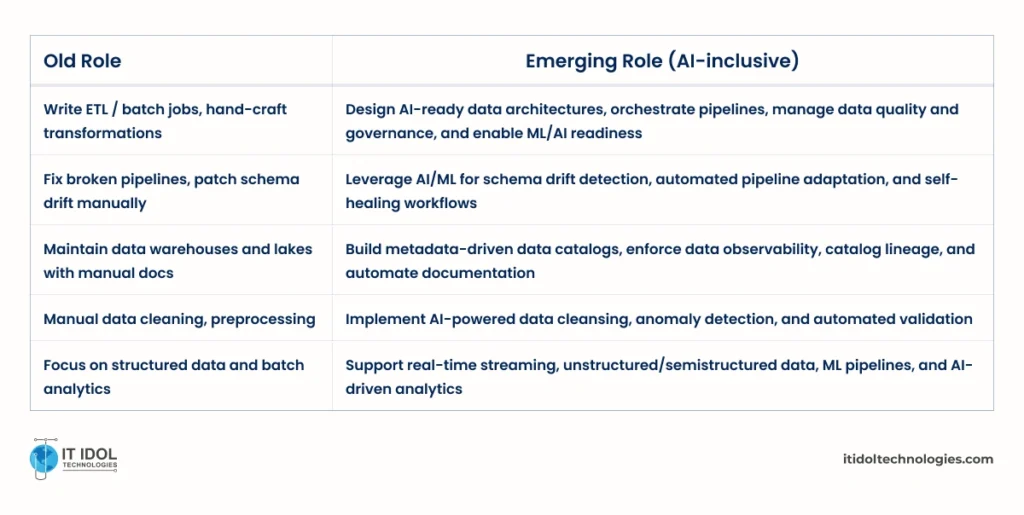
The Role of Data Engineers Is Evolving
Concrete Actions for Data Teams
1. Invest in AI-ready architecture now
Prefer metadata-driven, declarative, and modular pipelines over monolithic ETL jobs.
Adopt cloud-native, streaming, or event-driven architectures that can easily integrate AI-driven automation.
Build for flexibility schema changes, new data sources, and data volume spikes without rewriting pipelines.
2. Prioritize data quality, lineage, and governance
Use AI-powered tools to automate anomaly detection, data validation, and data cataloging.
Implement consistent data stewardship policies, access controls, and compliance tracking.
Treat data as a product governed, discoverable, and well-documented.
3. Upskill teams toward strategic, high-value tasks
Encourage data engineers to learn ML/AI fundamentals, metadata management, observability, and compliance.
Transition the team from “pipeline coders” to “data architects and stewards.”
Facilitate collaboration across roles: data engineers, data scientists, analysts, and compliance officers.
4. Treat AI adoption as a transformation, not simply tool adoption
Start with pilot projects, for example, AI-enabled metadata generation or schema drift detection, before migrating entire pipelines.
Audit existing pipelines, catalog current technical debt, and refactor key parts into modular, AI-compatible components.
Monitor and measure outputs: data quality, pipeline uptime, time to insight, compliance metrics, and team productivity.
Challenges, Risks, and What AI Can’t (Yet) Solve
While AI brings powerful capabilities, it doesn’t eliminate all challenges. Data teams must remain aware of limitations and risks:
Garbage In, Garbage Out: AI is only as good as the data it sees. Poor source data, inconsistent metadata, or missing context can lead to incorrect transformations or automation mistakes.
Governance, Compliance & Ethical Risks: AI-assisted automation doesn’t relieve responsibility; organizations still need human-led governance, compliance checks, and ethical oversight.
Trust, Transparency, and Explainability: AI-generated pipelines, transformations, or schema mappings may work, but teams must ensure transparency, testability, and maintainability. Black-box automation can backfire in regulated or security-sensitive environments.
Over-reliance on Tools, Losing Core Expertise: If data teams rely too heavily on AI for everything, they risk losing foundational skills: data modeling, performance optimization, and architecture design. This can lead to fragility when automation fails or when edge cases arise.
Integration with Legacy Systems & Vendor Lock-In: Many organizations have legacy databases, systems, and data workflows. Simply adding AI may not solve deep structural constraints; entire architecture changes may be needed, which is risky and expensive.
Takeaway: AI is a powerful enabler but not a silver bullet. Success demands combining AI capabilities with disciplined engineering, governance, human judgment, and continuous oversight.
How Organisations That Embrace AI-Enhanced Data Engineering Win
Organizations that proactively adapt their data engineering practices for the AI era unlock several strategic advantages:
Faster Time-to-Insight: With AI automating data pipeline generation, transformation, and maintenance, companies can deploy data products and analytics much faster, shortening cycles from weeks to days.
Higher Data Quality & Trust: Automated anomaly detection, data lineage, metadata cataloging, and observability reduce data errors, increase transparency, and build stakeholder confidence.
Scalable, Flexible Infrastructure: AI-ready, cloud-native pipelines enable organizations to adapt to increasing data volume/velocity, new data sources, and evolving business requirements without rewriting core infrastructure.
Operational Efficiency & Cost Savings: Automating manual tasks reduces engineering overhead, lowers maintenance costs, and enables small teams to handle large workloads.
Strategic Use of Human Capital: Data engineers shift from repetitive work to high-value tasks architecture, governance, data as a product, and collaboration with ML/AI teams.
In short, AI-enabled data engineering empowers organizations to treat data as a strategic asset, not a burden.
Conclusion
The myths surrounding data engineering that it’s only about writing ETL code, that it requires deep CS credentials, that AI will replace data engineers, or that AI integration is just a bolt-on are being dispelled by the rapid transformation unfolding in 2025. AI isn’t eliminating data engineering. It’s redefining it.
Today, data engineering is becoming a higher-level discipline: one focused on building resilient, adaptive, and governed data ecosystems that serve analytics, machine learning, and real-time decision-making. Data teams must adapt by investing in AI-ready architecture, enforcing data governance, and refocusing human expertise on strategy, oversight, and value creation.
Organizations that recognize this shift and invest accordingly stand to gain a powerful competitive advantage. Those who cling to outdated myths may find themselves left behind, still re-running fragile ETL jobs while others harness AI-powered data agility.
FAQ’s
1. Isn’t using AI for ETL and pipelines risky? What if it introduces bugs or data issues?
Yes, automation can introduce errors if not carefully monitored. AI can help generate code and infer schema, but human review, testing, observability, and continuous monitoring remain vital. Treat AI-generated transformations like any software: version control, unit/integration tests, documentation, and rollbacks must stay.
2. Will data engineering jobs become easier to get for non-CS people?
To some extent, yes. As AI automates boilerplate code and transformations, skills like data modeling, understanding business data, metadata management, and governance become more critical than deep computer science background. But candidates still need logical thinking, domain understanding, and data literacy.
3. If AI handles schema drift and pipeline adaptation automatically, do we still need data architects?
Absolutely. AI can catch schema changes and suggest adaptations, but decisions about data models, storage strategies, performance tradeoffs, compliance requirements, and architecture-level design still require human expertise. AI helps, but doesn’t replace architectural judgment.
4. How should organizations start migrating legacy ETL pipelines to AI-ready systems?
Begin with an audit: catalog existing data sources, pipelines, schemas, and technical debt. Then pilot AI-enabled tools on low-risk pipelines (e.g. metadata generation, schema change detection). Gradually refactor core pipelines into modular, metadata-driven architectures. Invest in governance, observability, and testing frameworks.
5. Can AI help with data governance and compliance (e.g., GDPR, HIPAA)?
AI can support governance, e.g., by detecting sensitive data, automatically tagging and classifying data, monitoring usage, and enforcing access patterns. But compliance requires human-led policies, audits, ethical oversight, and contextual interpretation. AI should assist, not replace, governance.
6. How does AI change the collaboration between data engineers, data scientists and analysts?
With AI automating pipeline plumbing, data engineers can focus more on building robust, shared data infrastructure. This promotes closer collaboration with data scientists and analysts around data modelling, feature engineering, real-time analytics, and ML/AI data readiness, breaking traditional silos.
7. Are there AI tools/platforms that data teams already trust for ETL and pipeline automation?
Yes. A growing number of AI-enhanced ETL and data integration tools (such as those listed by industry analyses) support schema mapping, data cleansing, streaming pipelines, and flexible metadata-driven data flows. (Integrate.io)
8. Does using AI for data engineering reduce costs or increase costs?
Mostly reduces cost in engineering hours, pipeline maintenance, debugging, and time-to-insight. But transitioning to AI-ready infrastructure may require upfront investment: tool costs, re-architecture efforts, new governance processes, and training. Long-term ROI tends to favour AI-enabled workflows.
9. What new skills should data engineers focus on to stay relevant in the AI era?
Focus on data architecture design, metadata modelling, data governance, observability, real-time streaming data, cloud-native and modular pipelines, ML/AI readiness, collaboration with analytics teams, and strategic thinking about data as a product.
10. If I’m building a small startup’s data stack, should I adopt AI-driven data engineering from day one?
Not necessarily. For very small teams or minimal data needs, traditional lightweight ETL and manual scripts may suffice. But if you expect growth, variable data sources, or eventual AI/ML workloads, designing for AI from the start (metadata-driven pipelines, modular architecture, observability) can save massive refactoring later and scale efficiently.
Parth Inamdar is a Content Writer at IT IDOL Technologies, specializing in AI, ML, data engineering, and digital product development. With 5+ years in tech content, he turns complex systems into clear, actionable insights. At IT IDOL, he also contributes to content strategy—aligning narratives with business goals and emerging trends. Off the clock, he enjoys exploring prompt engineering and systems design.